
AI PlaygroundでノーコードでRAGを試す
こんにちは。新卒3年目エンジニアの土屋です。
今回は、ElasticのKibanaのバージョン8.14(2024/06/06リリース)で使用できるようになった「AI Playground」についての記事です。
実際に使って試してみましたので、この機能の使い方とできることについてご紹介します。

AI Playgroundとは
「AI Playground」とはElasticsearch のデータを LLM(大規模言語モデル) と組み合わせて、手軽に検索拡張生成 (RAG) を行うことができるものです。
Elasticsearchの可視化ツールであるKinbanaでノーコードでRAGでのチャットを試すことができます。また、そのチャットの実装をPythonコードとして出力することもできます。
RAGについては過去のブログ「Gluegent Flowでどれを申請すれば分からなかったので、AIに聞いてみた」「生成AIのチャット回答精度を上げる方法」で紹介しています。
※「AI Playground」はまだテクニカルプレビュー段階の機能です。
必要なElastic環境
- Elastic v8.14.0以上のdeployment もしくは Elasticsearch Serverless project
対応するLLMプロバイダー
- Amazon Bedrock
- OpenAI
- Azure OpenAI
- OpenAI SDKと互換性のあるローカルLLM
今回はOpenAIと接続して試してみます。各LLMプロバイダーとの接続方法に関してはこちらで紹介されています。
OpenAIと接続する
Kibanaから Stack Management > Alerts and Insights項目のConnectorsを選択して「Create connector」を押します。
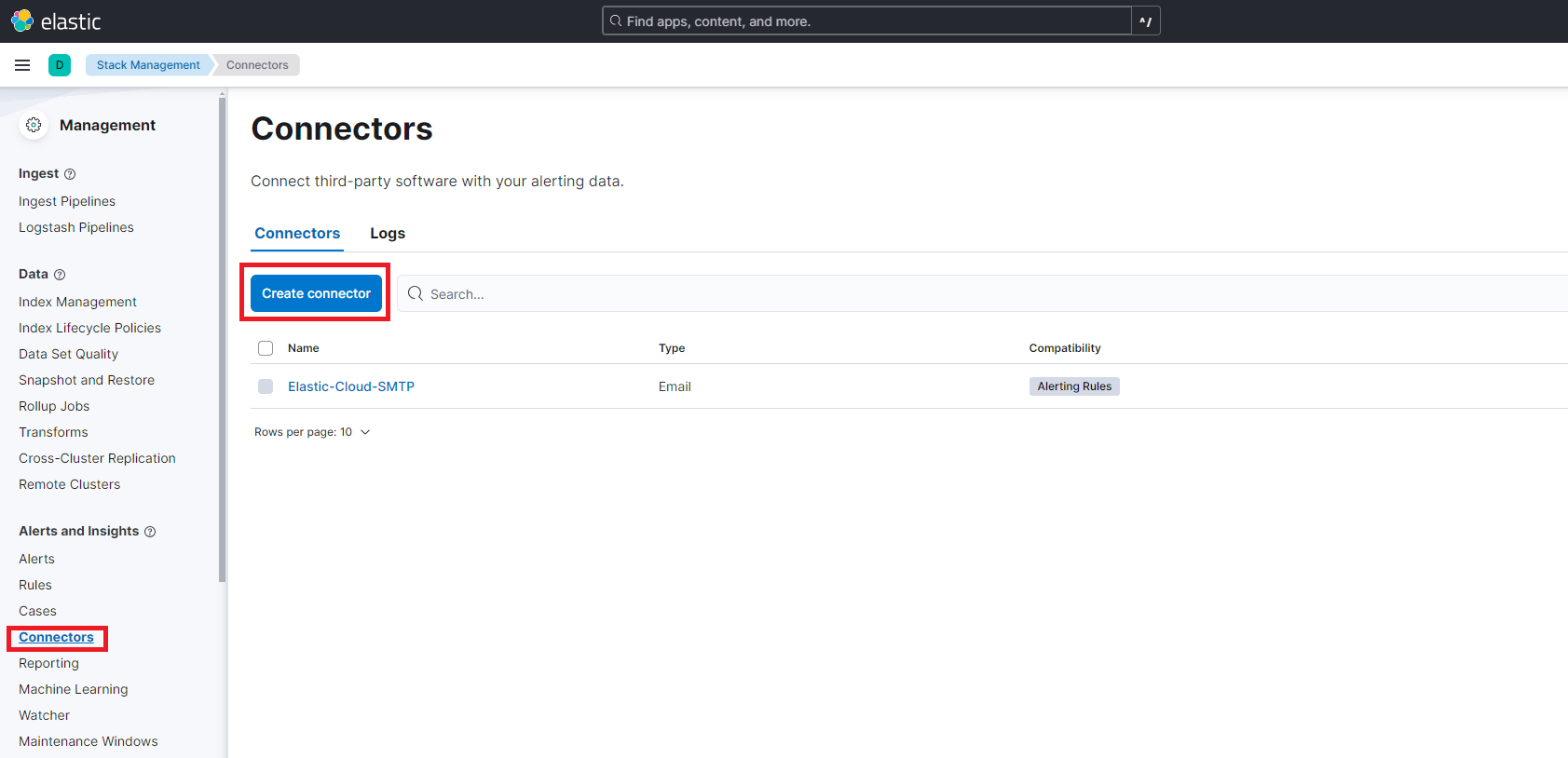
今回はOpneAIと接続したいので「OpenAI」を選択します。
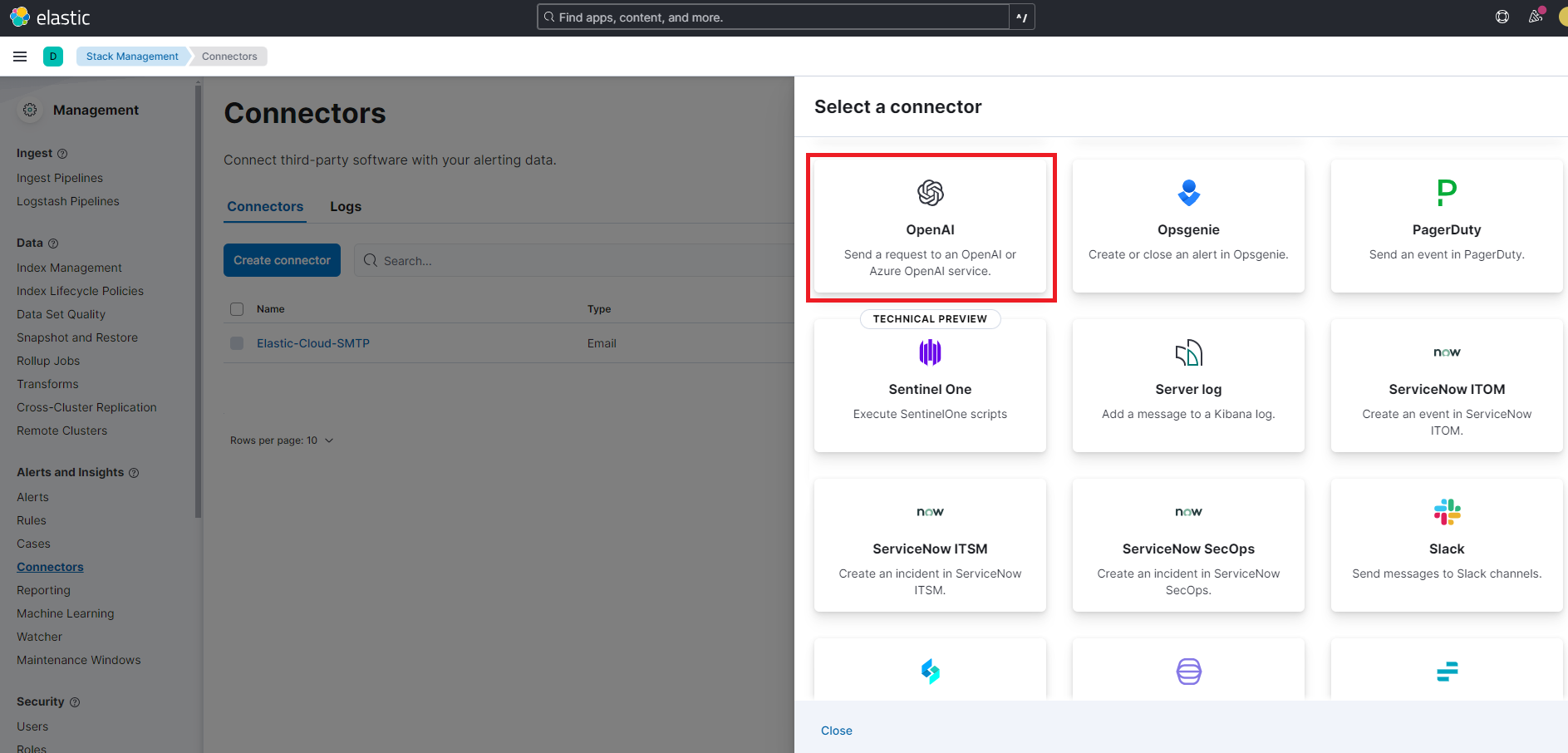
APIの接続情報と使用するモデルを入力します。OpenAI APIの場合はAPI Keyとエンドポイントの指定が必要です。
エンドポイントに関してはLLMプロバイダー毎にKibanaが自動で設定してくれています。リージョン等がエンドポイントの一部になっている場合は変更が必要な場合も有ります。OpenAI APIのエンドポイントとして「https://api.openai.com/v1/chat/completions」となっていたのでそのまま使います。今回は「gpt-4o」のモデルを使用します。
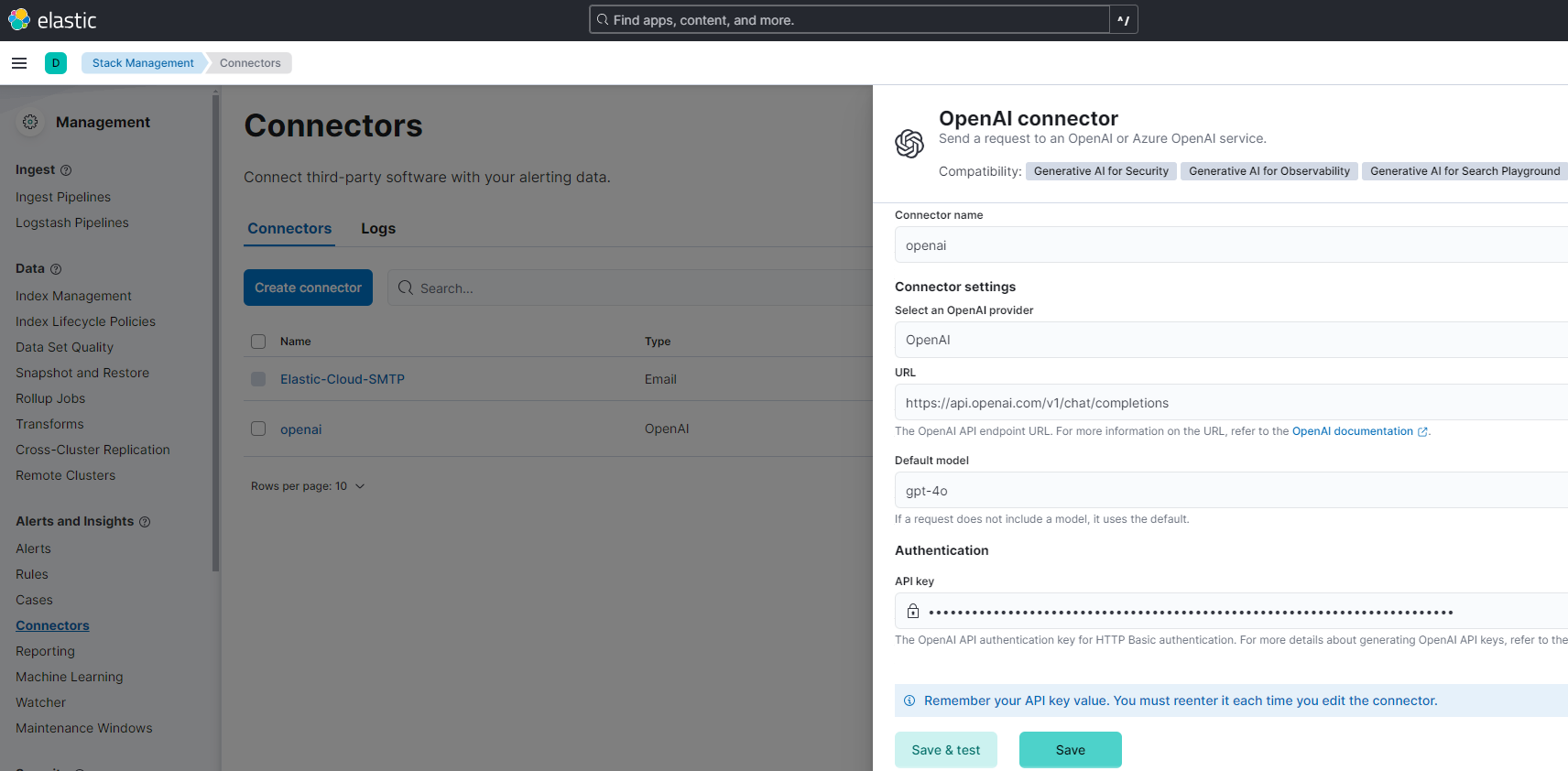
接続の確認をするために「Save & test」を押してみましょう
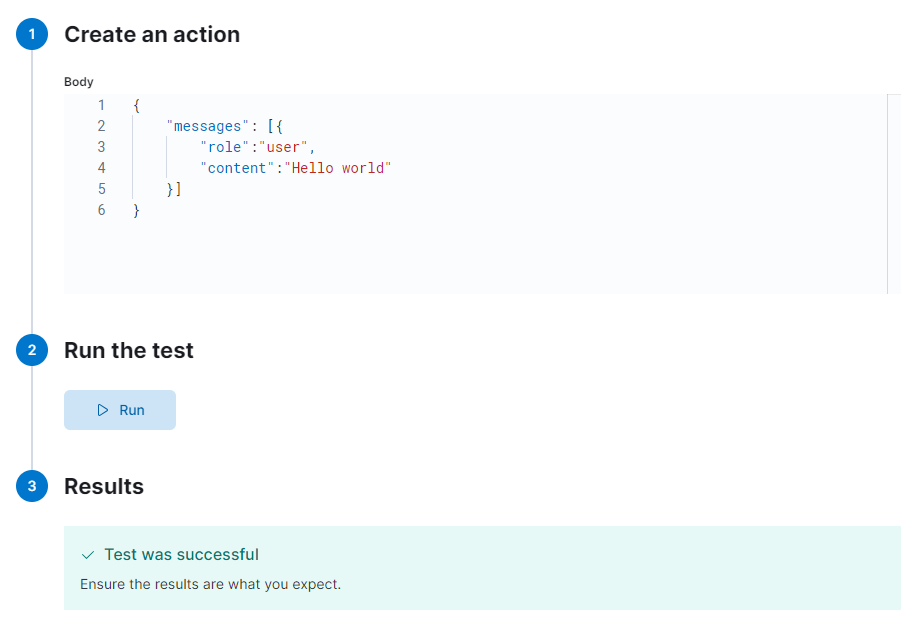
上の画像の様に「Test was successful」の表示がされればOKです。これでElasticsearchとOpenAIのコネクタの設定ができました。
Playgroundで使うインデックスの準備
今回は以下の5つのドキュメントをもつplayground_indexという名前のインデックスを作成しました。
{
"name": "神谷町 一郎",
"profile":"神谷町 一郎。神谷町家の長男。20歳。神谷町 二郎の兄"
}
{
"name": "神谷町 二郎",
"profile":"神谷町 二郎。神谷町家の次男。16歳。神谷町 一郎の弟。父は神谷町 港"
}
{
"name": "麻布 信二",
"profile":"麻布 信二。麻布家の次男。18歳。麻布 真一の弟"
}
{
"name": "六本木 雄一",
"profile":"六本木 雄一。六本木家の長男。19歳。神谷町 一郎の友人"
}
{
"name": "六本木 雄二",
"profile":"六本木 雄二。六本木家の次男。15歳。麻布 真一のクラスメート"
}Playgroundの使い方
SearchのBuild項目にある「Playground」を選択し、「Add data sources」を押して「playground_index」を選択する。
これでRAGを使ったチャットをすることができるようになりました。非常に簡単ですね!
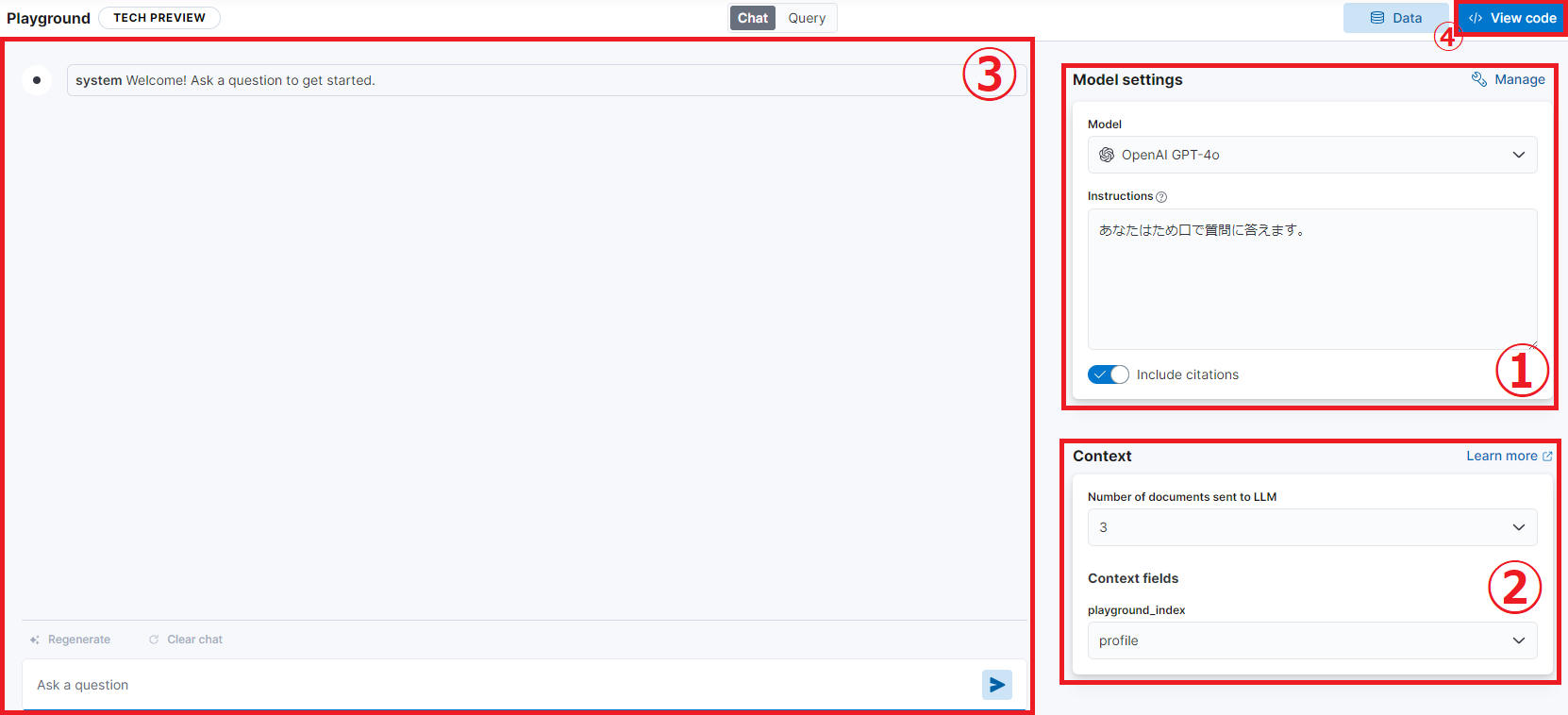
【画面の説明】
①Model settings:モデルの選択とInstructions入力ができます。今回は「GPT-4o」モデルを使い、Instructionsには「あなたはため口で質問に答えます。」という返答の仕方の指示を入力しました。
②Context:LLMに送るドキュメント数と Context fields を指定できます。今回は3つのドキュメントを使用し、Context fields には profile を指定します。これによって、チャットで送信する文章から profileフィールドに対して検索をし、ヒットした3件をLLMに送るようになります。
③チャットをする部分です。
④View code:チャットの実装をPythonコードで出力する
Playgroundで会話をする
実際にPlaygroundでチャットをしてみます。「神谷町 港の子供は誰ですか?」という質問をしました。
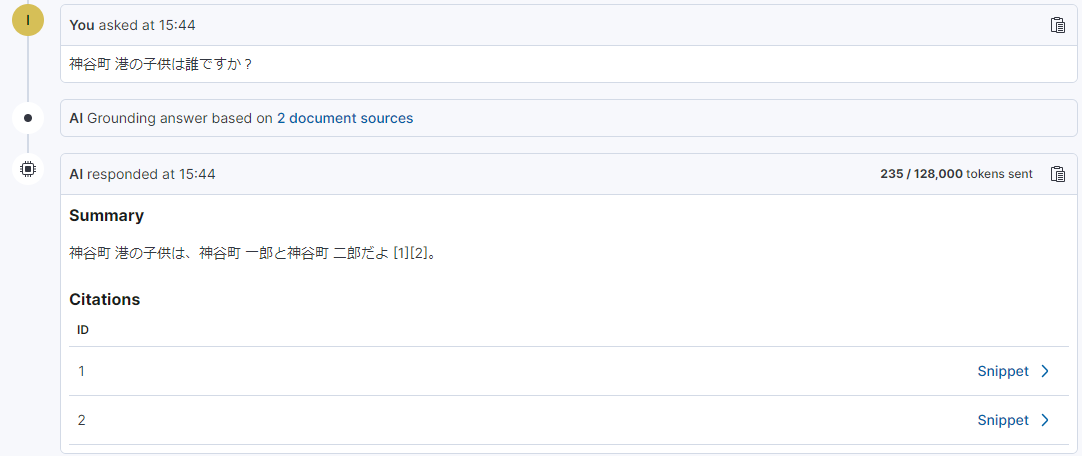
LLM(今回であればgpt-4o)が持っていない情報を質問の答えとして得ることができていますね。
神谷町 二郎のドキュメントには「父は神谷町 港」の記載はありますが、神谷町 一郎のドキュメントには「神谷町 二郎の兄」の記載しかありません。しかし、ドキュメントを総合的に判断して2人の子供に関して答えることが確認できました。「Grounding answer based on 2 document sources」とあるようにplayground_indexの2つのドキュメント情報でGroundingすることで回答を生成させています。Instructionsの指定によって返答の仕方はため口になっているのも確認できました。この後にそのまま会話を続けることもできました。
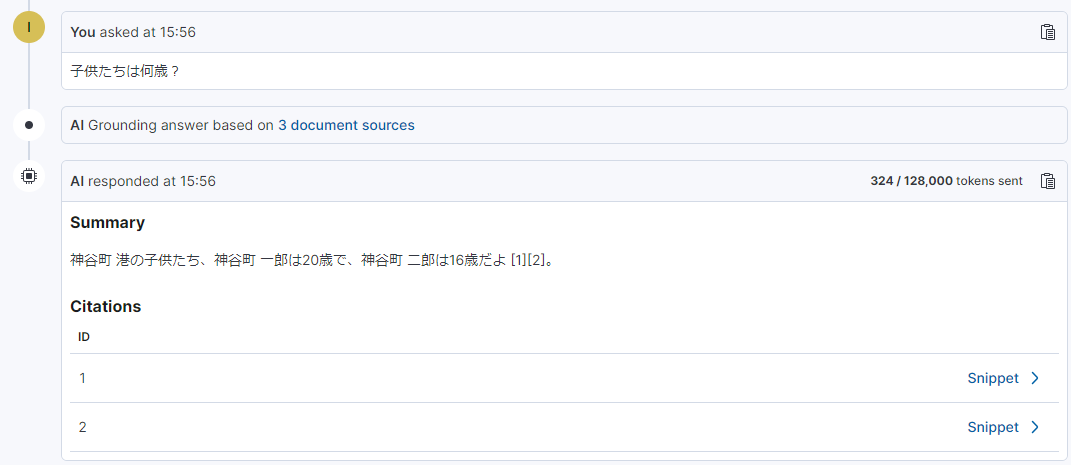
PlaygroundのRAG実装をPythonコードで出力する
「View code」を押すとRAGの実装をPythonコードとして表示させることができます。ElasticsearchのPythonクライアントを使用するかLangchainを使用するか選択することができます。
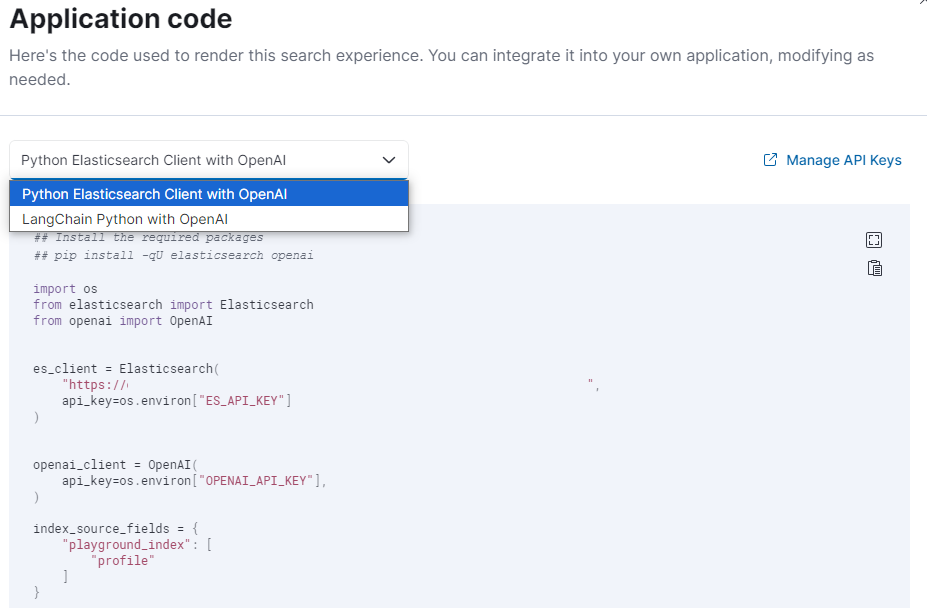
ローカルでこのPythonコードを実行することでも同様の回答を得られました。コードのクエリを見てみると”multi_match”を使用していました。検索部分に関しては以前に紹介したセマンティック検索に置き換えることでさらに柔軟な会話ができる様になりそうですね。
まとめ
今回はElasticのAI Playgroundを使用してノーコードでRAGを試してみました。LLMプロバイダーと連携させるだけで、Elasticsearchのインデックスを使用したRAGを簡単に試すことができるのは手軽で良いですね。Elasticsearchで管理しているデータが既にある場合は、そのデータを使用することができるので、AI活用のきっかけになりそうですね。実際に実装をする場合は、インデクシング時にエンベディングを使用するセマンティック検索を取り入れたり、複数の検索対象フィールドを指定したりと改良の余地はあると思いますが、Pythonコードを出力してくれるので細かい調整もできます。
今回試した機能等を使って今後Gluegent製品でもRAGを使用した機能の開発等もしていけたらと思います。最後まで読んでいただきありがとうございました。
参考:https://www.elastic.co/guide/en/kibana/current/playground.html
<お知らせ>
弊社が提供するクラウドワークフローGluegent Flowは、2024年11月より生成AIを活用した「ユーザーアシスト」機能を提供開始しました。
ご興味のある方は「ユーザーアシスト」機能の紹介ページをご覧ください。
(土屋)