
Elasticsearchでセマンティック検索

こんにちは。新卒二年目エンジニアの土屋です。
以前の私の記事ではElasticsearch環境をローカルで立ち上げる方法をブログにしましたが、今回はElasticsearchでセマンティック検索をする方法をご紹介しようと思います。
概要
今回はElasticsearch 8.0から登場した機械学習によるセマンティック検索をする方法を説明していきます。学習済みモデルの選択から実際に検索を試すところまでの手順をご紹介します。
セマンティック検索とは
単純な単語の一致検索だけではなく、検索文字の意味を理解して関連性の高い情報を検索結果として返す仕組みの事です。セマンティック検索を利用することで、よりユーザーの意図に沿った検索が可能になると期待されます。今回はこのセマンティック検索をテキストのエンベディング(ベクトル化)によって実現します。
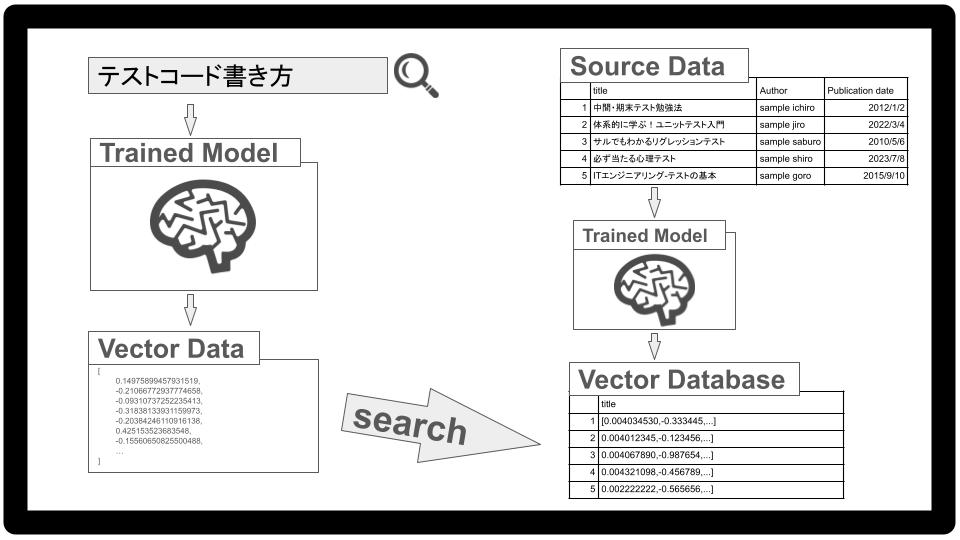
環境
今回は以前の記事で説明したローカル環境で起動したElasticsearchとKibanaを用いました。
使用PC
- OS:Windows 10 Pro
- 実装メモリ(RAM):16.0GB
- システム:64 ビット オペレーティング システム、x64 ベース プロセッサ
バージョン等
- Elasticsearch : 8.10.1
- Kibana : 8.10.1
- Python 3.9.13
1. Machine Learningの有効化
Machine LearningはElasticsearchのデフォルトのままの機能では使用できないのでMachine Learning機能を有効化する必要があります。
今回はローカル環境で立ち上げたElasticsearchのトライアル期間(30日)でMachine Learning機能を使ってみます。
KibanaのStack Management > Stack(License Management)からトライアルの有効化は可能です。
【Elastic Cloudの場合】
Machine Learning instancesを立てる必要があります。使用する学習済みモデルによってRAMのサイズ等の調整が必要になります。

2. Eland Python Clientのインストール
Elasticsearchに学習済みモデルをインポートするためのツールです。Pythonで動作するためPyPIからpipでインストールします。
|
python -m pip install eland[pytorch] |
参考:https://www.elastic.co/guide/en/elasticsearch/client/eland/current/index.html
3. Elandで学習済みモデルのインポート
今回はHugging Faceで公開されているBERTを元に学習された日本語に対応したモデルであるcl-tohoku/bert-base-japanese-v3を使用します。
Hugging Faceで公開されているモデルはElandを使って以下コマンドでインポート可能です。(ユーザー情報やElasticsearchのエンドポイントはお使いのものに書き換えてください。)
|
eland_import_hub_model --url http://localhost:9200/ -u elastic -p pswd --hub-model-id cl-tohoku/bert-base-japanese-v3 --task-type text_embedding |
※インポートする際にはモデルに必要なライブラリもインストールする必要が有ります。
(今回はunidic_liteとfugashiのpip installが必要でした。)
4. Kibanaでインポートしたモデルを同期・デプロイ
KibanaのStack Management > Machine Learning > Synchronize saved objectsからimportしたモデルを選択して同期してください。
同期するとTrained Modelsの一覧に表示されますので、インポートしたモデルのデプロイを開始します。

5. Ingest Pipelineの設定
インポートした学習済みモデルを使ってElasticsearchに登録するデータをエンベディングする場合はIngest Pipelineを使います。
以下のようにしてIngest Pipelineを作成します。このパイプラインはtitleフィールドのテキストをモデル「cl-tohoku__bert-base-japanese-v3」を使ってエンベディングしてtitle_vectorフィールドにエンベディング結果を入れるものとなっています。
|
PUT _ingest/pipeline/text_embedding_pipeline |
6. Indexのmapping設定
5.のパイプラインを使って登録されるベクトルデータはdense_vectorタイプで登録する必要があるため、以下のようにしてマッピングタイプの指定をしてください。dimsには使用する学習モデルに沿った次元数を設定します。(今回はconfig.jsonのhidden_sizeの値)
検索の際には検索クエリとの類似度を算出するのですが、この算出方法をsimilarityで選択することが可能です。ここではcos類似度を用いるようにしています。(参考:dense-vector-similarity)
後でベクトル検索と通常のmatch検索を比較するためにtitleはkuromoji_tokenizer(日本語に対応したtokenizer)を使用するようにしています。
|
PUT test_index |
7. Documentsの登録
ここまでできたら準備はできたのでドキュメントを登録していきます。今回は例として、「テスト」という文字が入った5つの架空の本のタイトルを登録してみます。登録方法は先ほど作成したパイプラインの指定をしてPUTするだけです。
|
PUT test_index/_doc/001?pipeline=text_embedding_pipeline |
8. セマンティック検索を試す
テキストエンベディングを利用してドキュメントの登録までできたので、後は検索してセマンティック検索の効果を体感してみます。
まずはセマンティック検索を使わずに検索ワード「テストコード書き方」で検索をかけてみます。
|
GET test_index/_search |
検索結果
|
"hits": [ |
セマンティック検索を用いていないため、単純に「テスト」という単語が一致した検索結果を返しています。
今回登録したドキュメントの場合「体系的に学ぶ!ユニットテスト入門」「サルでもわかるリグレッションテスト」「ITエンジニアリング-テストの基本」辺りがテストコードの書き方に関連しそうなものになると思いますが、単語の一致のみでは期待した結果が得られませんでした。
次にセマンティック検索を試します。dense_vectorフィールドへの検索はkNN(k最近傍法)を使う事で、検索文字列の意味と類似したものを取得します。各パラメータやkNNの仕組みに関しては公式サイトをご参照ください。
今回は以下のようにして検索しています。
|
GET test_index/_search
{
"knn": {
"field": "title_vector.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "cl-tohoku__bert-base-japanese-v3",
"model_text": "テストコード書き方"
}
}
},
"_source": ["title"]
}
|
検索結果
|
"hits": [
{
"_index": "test_index",
"_id": "006",
"_score": 0.9238725,
"_source": {
"title": "ITエンジニアリング-テストの基本"
}
},
{
"_index": "test_index",
"_id": "002",
"_score": 0.90138817,
"_source": {
"title": "体系的に学ぶ!ユニットテスト入門"
}
},
{
"_index": "test_index",
"_id": "003",
"_score": 0.8779657,
"_source": {
"title": "サルでもわかるリグレッションテスト"
}
},
{
"_index": "test_index",
"_id": "001",
"_score": 0.8776555,
"_source": {
"title": "中間・期末テスト勉強法"
}
},
{
"_index": "test_index",
"_id": "004",
"_score": 0.86641484,
"_source": {
"title": "必ず当たる心理テスト"
}
}
]
|
検索結果としては登録した全てのドキュメントが出てきましたが、今回はスコアリング結果が意味に沿った結果となりました。類似度が高い順にscoreが算出されていますね。単純な単語の一致検索ではなくセマンティック検索を用いる事で検索結果がユーザーの求めていたものになる事が確認できました。
まとめ
今回はElasticsearchでセマンティック検索をする方法をご紹介しました。本記事ではセマンティック検索が上手くできた例を取り上げましたが、全ての場合で意味通りの検索結果が返ってくるのは難しく、検索の精度を上げるためにはモデルの選定や各種パラメータの設定、一致検索との組み合わせ等が必要になると思います。しかし、公開されている学習済みモデルや自分で学習させたモデルをElasticsearchで手軽に活用できる事は非常に良いですね。
最後まで読んで頂きありがとうございました。
(土屋)